Research Report
Uncovering Intracultivar Genetic Variability in Soybean Applying Phenotypic and Genomic Approaches 
2 Universidade Federal de Lavras, Lavras-MG, 37200-900, Brazil
3 GDM Genetica do Brasil S.A., Cambé-PR, 86183-751, Brazil
 Author
Author  Correspondence author
Correspondence author
Legume Genomics and Genetics, 2026, Vol. 17, No. 1
Received: 09 Feb., 2026 Accepted: 28 Feb., 2026 Published: 11 Mar., 2026
We aimed to understand and explore the intracultivar variability of soybean lines by conducting both phenotypic and genotypic analyses. During the 2017/2018 crop season, plants from six soybean cultivars (SYN1359S IPRO, P98Y11, BMX6160, 97R73 RR, NS7000 IPRO, and NA5909) were used to establish the genetic treatments. For each of these six cultivars, 47 plants were selected to generate progenies and, along with the controls, were subjected to trials across two subsequent crop seasons, 2018/2019 and 2019/2020. Phenotypic traits such as Grain Yield (YIELD), Full Maturity (FM), Days to Flowering (DF), and Plant Height (PH) were measured. Additionally, 288 samples (progenies and controls) were genotyped using a chip containing 1329 SNPs using the Ion S5™ XL System. Phenotypic data were analyzed using mixed models. The genotypic analysis included measures such as observed and expected heterozygosity, hierarchical clustering (UPGMA), and principal component analysis (PCA). The study reveals the existence of both phenotypic and genotypic intracultivar variation among the assessed cultivars. The degree of variation observed differs, with cultivars P98Y11 and NA5909 exhibiting higher levels of diversity, while NS7000 presents a lower level of variation. Given the found variations selection can be employed for soybean breeding to achieve fast and directed gains, as well as to identify genotypes adaptable to specific environments.
1 Background
Soybean (Glycine max [Merr.] L.) is the most important oilseed crop worldwide, valued for its oil (18%) and protein (36%) content (Duan et al., 2023). Since 2020, Brazil has been the world’s leading producer, and in the 2024/2025 crop season it accounted for 169 million tons (USDA, 2025). This achievement results from several factors, including improved crop management, greater investment in research and technology, and advances in breeding (Medina et al., 2016). To meet market demands, the ultimate goal of breeding programs is the selection of superior genotypes, and the programs may follow different methods, such as hybridization, pure-line selection, and germplasm introduction.
Pure line selection isolates the best genotypes from a heterogeneous population by selecting individual plants and evaluating their progenies. In this process, no new genotype is created, as the goal is simply to identify and preserve superior genotypes within the existing population (Reynolds and Braun, 2016). This breeding strategy has been studied in several self-pollinated species, such as soybean (Amaral et al., 2019), common bean (Santos et al., 2002), wheat (Agorastos and Goulas, 2005), and rice (Roy et al., 2016). Selection of pure and highly homozygous lines is a fundamental objective in plant breeding programs. In soybean, lines are typically developed to serve as cultivars; however, their long-term genetic stability may be affected by intracultivar variability, which can arise through genomic and structural modifications over time (Tokatlidis, 2015). Intracultivar variation has been increasingly documented in autogamous crops, including soybean (Amaral et al., 2019), bean (Santos et al., 2002), wheat (Agorastos and Goulas, 2005), and rice (Roy et al., 2016), reinforcing that “pure lines” may not be entirely genetically uniform.
Several mechanisms can contribute to this variability, including residual heterozygosity, spontaneous mutations, activity of transposable elements, epigenetic modifications, occasional cross-pollination, and chromosomal alterations (Tokatlidis, 2015). These mechanisms introduce genomic changes that may lead to phenotypic divergence within cultivars, potentially affecting their stability but also providing novel sources of variation for breeding. Among these processes, residual heterozygosity (RH) is particularly relevant. Under continuous self-fertilization, the proportion of heterozygous loci is expected to decrease by half each generation. Thus, after seven selfing generations, approximately 99.2% of the loci should be homozygous. Even so, the persistence of low-frequency heterozygous loci can still result in segregation, giving rise to detectable phenotypic and physiological variation.
The development of new soybean cultivars requires substantial investment and time. In this context, evaluating and selecting superior plants within existing cultivars has emerged as a cost-effective breeding strategy, enabling breeders to derive one or more purified lines that may outperform or replace the original cultivar. Such lines retain agronomically relevant traits already recognized by farmers while exhibiting greater predictability, uniformity, and a higher degree of homozygosity. Therefore, this study investigates the extent of intracultivar variability in six soybean cultivars using phenotypic and genotypic data to assess their genetic stability and potential impact on breeding.
2 Results
2.1 Phenotypic data
For individual analysis (data not shown), results were divided by cycle: early and late-maturity. In early-maturity cultivars, significant differences were observed for YIELD and FM in the 2018/19 season across tests, progenies, populations, and among early populations. In 2019/20, YIELD showed significant variation within tests, populations, and notably within SYN1359. Plant height differed significantly among NA5909 progenies, while DF differences were exclusive to NA5909. For late-maturity cultivars, in 2018/19, YIELD showed significant differences within tests, progenies, populations, and among late populations. In 2019/20, all traits differed significantly within the variety 97R73 and at the progeny level. Additionally, 98Y11 showed significant differences for YIELD and plant height.
Progeny selection accuracy ranged from medium to high, with YIELD accuracy varying from 0.35 (EARLY 19/20) to 0.82 (LATE 18/19). Population selection accuracy (rgĝpop) which measures the accuracy of selection at the population level, exhibited high magnitudes, with values ranging from 0.71 to 0.51 (data not shown). These estimates for the variables, in general, were higher for the late-maturity group in both years. The estimates of CVe ranged from 1.13 for FM, (LATE 19/20) to 17.91 for YIELD, (EARLY 18/19). The CVgprog is relatively low compared to CVgpop, suggesting more variation among populations than within for most of the traits. In the multi-environment analysis (Table 1), a significant variation was detected for progenies for the traits YIELD, PH, and FM. Variation was detected among populations for all traits, as well as between early and late maturity cultivars.
.png) Table 1 Results for the multi-environment analysis for grain yield (YIELD), plant height (PH), full maturity (FM) and days to flowering (DF). Note: SV: Source of variation; MStest- mean square of checks, σ2Prog- progenies variance, σ2Pop- population variance, Variance among σ297r73, σ2NS7000, σ298Y11, σ2BMX6160, σ2SYN1359, σ2NA5909, σ2BMX6160) σ2e residual variance, DF and FM (days); PH (cm); YIELD (Kg ha-1); Wald test for fixed effects (F) and LRT (Likelihood Ratio Test) for random effects (R); "ns" indicates 'not significant', whereas asterisks (*) indicate levels of significance, with one asterisk for p < 0.05 and two asterisks for p < 0.01. σ2Pop: Heritability among populations; h2Prog: heritability within populations modified; h²total: total heritability = heritability among + within populations modified; rgĝprog: accuracy on the progeny-mean basis; rgĝpop: accuracy on the population; rgĝtotal: accuracy total; CVpop: population coefficient of variation in percentage; CVprog: coefficient of variation of progeny or progeny within population, in percentage terms; CVe : experimental coefficient of variation in percentage terms |
The variation among progenies within each population was significant for all traits for the late maturity cultivars 97R73 and NS7000. For the cultivars 98Y11, NA5909 and BMX6160, the variation was detected for PH, FM and DF. In addition, for SYN1359, the variation was detected for all traits except for PH. The environmental variance (σ2e) was not significant for YIELD and PH, but was significant for FM and DF. In contrast, the interaction (σ2GxE) was significant for YIELD, FM and DF, whereas it was not significant for PH. The progeny heritability (h2Prog), ranged from low, FM (0.12) and YIELD (0.17), to medium, DF (0.45) to high, PH (0.86). Nonetheless the population heritability (σ2Pop) ranged from low, YIELD (0.18) to high, PH (0.96), FM (0.86) and DF (0.96), in this regard at population level all the traits showed higher heritability. These results followed the same pattern for accuracy, where total accuracy (rgĝtotal) ranged from medium, YIELD (0.55) to high, PH (0.99), FM (0.94) and DF (0.99).
2.2 Genetic diversity and population structure
UPGMA clustering of the 267 progenies revealed close genetic relationships among cultivars due to shared ancestry (Figure 1). The cophenetic correlation coefficient was 0.92 and significant (Mantel test), indicating that the dendrogram accurately represents the genetic distances among progenies, with minimal distortion introduced by the clustering method.
.png) Figure 1 Hierarchical cluster analysis dendrogram of 267 soybean genotypes based on provesti’s absolute genetic distance, derived from the analysis of 605 SNP markers, with the mojena test applied to determine the optimal number of clusters |
The first two principal components accounted for 47.11% of the total genetic variability (Figure 2). The analysis revealed six major clusters corresponding to the origins of the progenies from previous cultivars.
.png) Figure 2 Principal component analysis (PCA) scatter plot of pairwise genetic distances among 267 progenies using 605 SNP markers |
The results on Table 2, showed the genetic variation among soybean progenies, these findings are consistent with the PCA results. High He and Ho values in P98Y11 and NA5909 indicate a broad genetic base suitable for intracultivar selection, while the low diversity in NS7000 (He = 0.047725; Ho = 0.032058), also reflected in its low dispersion in the PCA, may limit selection potential.
.png) Table 2 Heterozygosity metrics for genetic diversity assessment within populations using 605 SNP markers. It includes information on expected Heterozygosity (He), and observed Heterozygosity (Ho) |
3 Discussion
3.1 Phenotypic data
Phenotypic variation within cultivars has been reported in soybean (Fasoula and Boema, 2005; Tokatlidis, 2015; Amaral et al., 2019; Achard et al., 2020) and other crops such as potato, wheat, cotton, and barley (Tokatlidis et al., 2008; Marand, 2019; Ninou et al., 2022). This phenotypic variability, even within cultivars, highlights the importance of understanding the genetic basis of traits to improve selection strategies. Consistent with this premise, the evaluation of late-maturing cultivars in both 2018/19 and 2019/20 revealed significant differences not only among cultivars but also within them. In 2018/19, yield differed significantly across the test, progenies, and populations, as well as between the three late maturity cultivars. In 2019/20, this pattern was reinforced, with significant differences detected for all traits within the cultivar 97R73, and at the progeny level for all evaluated traits.
Ninou et al. (2022) found significant variation within improved commercial cultivars of durum wheat for grain yield and protein content. Similarly, significant intracultivar differences over two years and among three locations were observed for cotton yield. The same study also identified intracultivar variation for fiber quality traits such as length and micronaire, while fiber strength and uniformity showed no significant variation. Physiological traits like leaf carbon isotope discrimination, ash content, and potassium concentration also exhibited intracultivar variation (Tokatlidis et al., 2008). Heritability, quantifies the proportion of phenotypic variance explained by genetic differences. In the multi-environment analysis, heritability and accuracy were highest for PH. Indicating strong genetic control and suggesting that effective selection is feasible at the progeny level.
In contrast, the coefficient of variation due to environmental effects (CVe) was very low for FM and DF, showing the greatest precision for this trait (Table 2). Low heritability was observed for YIELD, as expected, since it is a quantitative trait strongly influenced by environment, which is consistent with the findings of Mendonça et al. (2020).
The lower heritability for YIELD (0.17) and FM (0.12) at progeny level, in the multi-environment analysis, indicates that these traits are strongly influenced by environment. Nonetheless, the detection of significant genotypic variance for both traits demonstrate the presence of exploitable genetic variability. The low coefficients of variation (3.49 for YIELD, 0.43 for FM) confirm the precision of phenotypic assessments and strengthen the reliability of the results.
Soybean maturity is a complex trait controlled by the interaction of numerous genes, molecular pathways, and the cultivation environment, in the study of Zimmer et al. (2021), several QTL’s associated with maturity groups were identified across different chromosomes, including loci with effects spanning multiple maturity groups. Similarly, soybean seed yield is also a complex quantitative trait governed by multiple genes and broadly influenced by growing conditions and latitudinal adaptation (Tayade et al., 2023). The complexity of both traits explains the low heritability, as their phenotypic expression results from intricate gene-environment interactions. Besides the trait itself, the genetic structure of a population is also crucial in heritability estimation. In self-pollinated plants, we often see high heritability within a population due to homozygosity at many loci, reducing genetic variation for certain traits and making the individuals more genetically similar to each other (Falconer and Mackay, 1996). This higher heritability within a population is present in Table 2.
The investigation of intracultivar variation in soybeans has disclosed several key insights that have implications for soybean breeding and cultivation. The potential for selection within a cultivar stands out as a promising avenue for enhancing desirable traits while maintaining the overall genetic elite background of the cultivar. This potential for selection within a soybean cultivar also raises important considerations in the context of plant variety protection. To qualify for protection under plant variety protection laws, a new cultivar must typically meet the criteria of Distinctness, Uniformity, and Stability (DUS). Another perspective that emerges when considering intracultivar variation is the multiline cultivars. This strategy aims to enhance yield stability and bolster resilience against both biotic and abiotic stresses. For several soybean breeding programs, the bulk method is commonly employed to manage segregating populations through to the F3 or F4 generations. This approach is also used during the evaluation of progenies within families. As a result, the cultivars that are developed under these conditions are, in essence, a composite of multiple lines rather than a single, pure line (Tokatlidis, 2015). Studies using multiline approach has demonstrated that such cultivars are markedly stable (Carneiro et al., 2019) and effective in reducing the severety of asian soybean rust (ASR) (Vilela et al., 2024).
3.2 Molecular data
Phenotypic variation within cultivars has Several studies have demonstrated intracultivar variation using molecular tools. Yates et al. (2012) used SSR markers to analyze three soybean cultivars and confirmed heterogeneity in protein and oil content, as well as in fatty acid composition, as previously reported by Fasoula and Boerma (2005). The majority of intracultivar SSR variation was attributed to residual heterozygosity, resulting in allele polymorphism. Additionally, Achard et al. (2020), employed SNP markers to assess intracultivar variation in a study involving 36 cultivars and 5 346 SNPs, revealing heterogeneity levels ranging from 0 to 10%.
Mihelich et al. (2020) conducted a heterogeneity analysis of 20.087 Glycine max and Glycine soja accessions from the USDA Soybean Germplasm Collection (SGC). The study identified high probability intervals of heterogeneity in 4% of the collection, corresponding to 870 accessions. However, the 'Williams 82' soybean accession showed no evidence of heterogeneity, in contrast to the within 'Williams 82' variation reported by Haun et al. (2011). The researchers proposed three explanations for the absence of intra-accession variation in 'Williams 82': a genetic bottleneck causing a specific population homogeneity distinct from other varieties; sampling of genetically identical individuals or derivation from a single, non-representative plant. This lack of heterogeneity in 'Williams 82' suggests that similar processes could have also obscured the true genetic diversity in other accessions within the SGC.
In this study, genotypic variation is consistent with phenotypic variation. Progeny derived from P98Y11 and NA5909 exhibited significant variations for PH, FM, and DF in multi-environment analysis. So, a considerable genetic diversity was found for a within P98Y11 and NA5909 population analysis, indicating substantial genetic diversity in these populations. Furthermore, at an individual level, they displayed considerable variation for yield and plant height.
Cultivars 97R73 and P98Y11 were grouped together because they both originated from the same breeding company (Corteva-Pioneer). Even though they have different maturity groups, the genetic background could be similar. In contrast, the cultivars NA5909 and NS7000 IPRO exhibit differences, and despite both originating from the same breeding company (Syngenta-Nidera), this variation may be due to the cultivars being derived from different relative maturity groups (RMGs). These findings agree with those reported by Mendonça et al. (2022), indicating that varieties from the same breeding company, particularly those from identical RMGs, have substantial genetic similarity.
The PCA analyses revealed six major clusters corresponding to the origins of the progenies from previous cultivars. A distinct separation of cultivars 97R73 and P98Y11 from the others corroborates with the dendrogram findings. Notably, the PCA provided a visualization of the high level of variation within the P98Y11 and NA5909 populations, as evidenced by the larger ellipses representing these groups. Conversely, the progenies derived from NS7000 exhibited the smallest variation. This intra-cultivar variation for P98Y11 and NA5909 can be explained by various mechanisms such as residual heterozygosity, mutations, transposable elements, epigenetic modifications, non-homologous recombination, and chromosomal mutations (Tokatlidis, 2015), and may also be influenced by genetic drift, especially in populations with reduced effective size. In addition, mechanical admixture may have occurred during seed production, and although with low probability, cross-fertilization can also take place, leading to the formation of hybrid seeds (Ahrent and Cavivess, 1994).
In this context, the study of Mihelich et al. (2020), detected residual heterozygosity in all evaluated accessions of soybean, although at varying levels depending on the accession type. Landraces exhibited the highest level (5.2%), followed by North American cultivars (4.8%), whereas G.soja, showed the lowest level (0.6%). Studies by Du et al. (2010), through SoyTEdb, identified that approximately 42% of the genome corresponds to class I transposable elements (retrotransposons) and 16% to class II transposable elements (DNA transposons). Moreover, epigenetic modifications have proven to be fundamental, contributing to the adaptive responses of soybean under different environmental stresses (Fang et al., 2025).
The genetic variation among soybean progenies derived from six cultivars was assessed by calculating expected heterozygosity (He) values for each population. These He values ranged from 0.047725 in NS7000 to 0.124485 in P98Y11. Additionally, observed heterozygosity (Ho) values were determined for each population to assess the genetic variation within the soybean progenies. The Ho values varied from 0.032058 in NS7000 to 0.112448 in P98Y11, as shown in (Table 2). These findings are consistent with the PCA results, which indicated significant variation in cultivars P98Y11 and NA5909, as reflected by high He and Ho values, indicating a broad genetic base, which suggests potential for intracultivar selection. Conversely, the NS7000 population exhibited the lowest genetic diversity with an He value of 0.047725 and an Ho value of 0.032058 also evidenced by the low dispersion of data points in the PCA. This suggests a more uniform genetic structure within this population (Lu et al., 2022).
Remaining heterozygosity (HR) has been identified as an important source of intracultivar variation. In bulk breeding, segregating populations are advanced through successive generations of selfing, with the expectation that heterozygosity will be reduced by half each cycle until reaching near fixation. However, studies have shown that natural selection may preserve heterozygous loci when they confer adaptive advantages, as observed by Hockett et al. (1983) even in advanced generations. This indicates that, despite the inbreeding process inherent to the bulk method, HR can persist within families and contribute to phenotypic variability, which may be exploited during selection in later generations. A study carried out by Fasoula, Yates, and Boerma (2012) using SSR markers in soybean cultivars found 82% to 93% variation attributable to HR. However, even in 100% homogeneous lines, variation can be found, resulted from mutation, intragenic recombination, unequal crossing over, DNA methylation, excision or insertion of transposable elements, and gene duplication (Morgante et al., 2005; Sandhu et al., 2017; Salgotra and Chauhan, 2023).
Another hypothesis is that the genome is dynamic and that new genotypic and phenotypic variation arises in each generation. One source of variation is genetic change leading to alleles with modified effects, that is, de novo generated variation. A second, complementary source of variation could come from interaction or epistatic effects, involving both de novo diversity and the original genetic diversity (Rasmusson and Phillips, 1997). Given that phenotypic and genotypic variations have been observed across all populations, selection can be employed for soybean breeding to archive fast and directed gains, as well as to identify plants adaptable to specific environments.
4 Materials and Methods
4.1 Plant material and field trials
The experiments were carried out at the Muquém Farm of the Federal University of Lavras (UFLA) (21°14' S; 45°00' W), Lavras, MG, Brazil, in the 2017/2018 crop season, with the selection of plants from the SYN1359S IPRO, P98Y11, BMX6160, 97R73 RR, NS7000 IPRO, and NA5909 cultivars. Each cultivar was grown in a population scheme consisting of 500 plants per cultivar. To optimize the experimental process, 80 plants were collected from each population, and out of these 80 plants, a total of 47 were selected for the progeny trials. These progenies were then evaluated alongside control samples across two cropping seasons, 2018/2019 and 2019/2020. These progenies represent new lines derived from individual plants within the original cultivars, whereas the cultivars themselves were used as controls to represent the original commercial materials (Table 3).
.png) Table 3 Soybean cultivars used for obtaining the evaluated progenies, MG (maturity group) |
4.2 Experimental design
The experiment was carried out in 2018/2019 cropping season using an incomplete block design (IBD). Specifically, a simple 17x17 lattice arrangement was employed, totaling 288 treatments, which included 282 progenies and 6 control varieties, corresponding to the original commercial materials: SYN1359S IPRO, P98Y11, BMX6160, 97R73 RR, NS7000 IPRO and NA5909. The experimental plots consisted of single rows, 2 m length and 0.5 m apart. In the 2019/20 cropping season, the progenies were split into two experiments based on their maturity group: early and late. The early experiment included 46 progenies from each of the early-maturing cultivars (SYN1359S IPRO, BMX6160, and NA5909), as well as the six control cultivars. The late experiment comprised 46 progenies from each of the late-maturing cultivars (NS7000, P98Y11, and 97R73), along with the same six control cultivars. Both experiments were conducted with three replications in a 12x12 lattice design. Each experimental plot consisted of two rows, 2 m in length and 0.5 m apart.
The following traits were assessed: (1) Grain Yield (YIELD): was quantified as the amount harvested from each plot and expressed in kg/ha at 13% moisture content; (2) Days to Flowering (DF): was the number of days from sowing to the R2 stage, at which point 50% of the plants exhibit full flowering; (3) Full Maturity (FM): was the number of days from sowing until the R8 stage (full maturity) is reached, defined as the point when 90% of the plants in the plot have attained this stage, according to the criteria set by Fehr and Caviness (1977) and (4) Plant Height (PH): was measured in cm from the base to the uppermost leaf insertion. Three plants were randomly selected from each plot for measurement.
4.3 Phenotypic data analysis
Data were analyzed adopting a mixed-model approach. The experiments from each year, categorized according to relative maturity groups, were analyzed individually using model one.
(1) y=μ+Xrτr+Xtτt+Xgug+Xbub+Xpup+ε
Where y: Observed value of the analyzed trait, μ: constant associated with all observations, Xrτr: vector of replicate fixed effect, Xtτt: vector of checks or test fixed effect, Xgug: vector of progenies effect (random), g~N(0,Iσg2), Xbub: vector of block effect aligned with replications (random), b~N(0,Iσb2), Xpup: vector of population effects the six cultivars (random), p~N(0,Iσ2p) and ε: vector of associated error effect (random), ε~N(0,Iσε2).
Residual normality was verified using the Shapiro-Wilk test (Shapiro and Wilk, 1965), and homogeneity of variances across experiments was assessed using Hartley's maximum F test (Hartley, 1950). The joint analysis across environments was then performed using model two.
(2) y=μ+Xrτr+Xcτc+Xtτt+Xpup+Xaua+Xgug+Xgauga+Xbub+ε
Where: y: Observed value for the analyzed trait, μ: constant associated with all observations, Xrτr: vector of replicate fixed effect, Xcτc: vector of maturity group fixed effect, Xtτt: vector of checks or test fixed effect, Xpup: vector of population effects the six cultivars (random), b~N(0, Iσp2), Xaua: vector of environment effects the years (random), a~N(0, Iσa2), Xgug: vector of progenies effect (random), g~N(0, Iσg2), Xgauga: vector of interaction effect progenies × environment (random), ga~N(0, FA1⊗Iσga2), Xbub: vector of block effect alignewith replications
(random) b~N(0,Iσb2), and ε: vector of effect of associated errors (random), 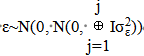 .
.
The residual variance-covariance matrix was modeled with a diagonal structure to account for heterogeneity identified within the dataset. Subsequently, the variance-covariance structure for the genotype-by-environment interaction was modeled using an extended form of the factor analytic (FA) approach. The most suitable model was selected based on the Bayesian Information Criterion (BIC) and the Akaike Information Criterion (AIC). Progeny, population and total heritability were estimated. Accuracy was calculated at three levels: population, progeny, and overall accuracy. Additionally, the coefficient of variation of the experimental error was determined for each evaluated variable to assess the precision and consistency of the data.
4.4 DNA extration, library preparation and sequencing
The seeds of the 288 genotypes were sown in trays and placed in a growth chamber maintained at 25°C. The seeds were grown until the emergence of the first trifoliate and six leaf punches were collected from each genotype. The samples were immediately frozen and stored at -80°C. Subsequently, the samples were lyophilized (freeze-dried) to remove moisture. DNA extraction and genotyping were conducted using the KLEARGENE commercial kit (LGC Group, Teddington, England). A customized Ion AgriseqTM target GBS panel was used to genotype 1329 single nucleotide polymorphism (SNP) markers.
The library construction was performed using ThermoFisher’s protocol which uses 5 µL AmpliSeq Panel, 2 µL 2x Ion AgriSeq Amplification Mix, and gDNA (10 ng/rxn). The target amplification depends on the of the number of targets for this panel size, 15 cycles were used, consisting of 99°C for 15 seconds of denaturation and 60°C for 8 minutes forannealing and extension. Barcode Reaction Mix from ThermoFisher was used with 1 µL of barcode enzyme and 2 µL of barcoding buffer that was used with IonCode™ Barcode Adapters. The barcode ligation was performed running the program 22°C for 30 minutes and 72°C for 10 minutes. Samples pools were created, and library cleanup and normalization were performed.
A two-round AMPure clean-up was done. First, 1.5X AMPure clean-up was added to remove previous residual reagents, 2X 70% Ethanol washes and Elute in Low TE. Then a second round was performed with 1.2X AMPure clean-up, 2X 70% Ethanol washes and elute in normalization master mix and 9-cycle PCR 98°C for 15 seconds of denature and 64°C for 1 minute for annealing and extension. Normalization clean-up brings all libraries to the same concentration (200 pM) so they can be pooled 1:1. The purified and normalized libraries were prepared for loading into the Ion Chef system, which automates template preparation and chip loading for the ION S5 sequencer. The final step was sequencing those libraries on Ion GeneStudioTM S5 Prime, which can deliver up to 80 million reads per run. Bioinformatic analysis was then performed using Torrent Suite™ Software, which processed the sequencing data on a computer connected to the Ion Torrent™ server v.5.12.3. The outcome of this analysis was a matrix, listing the genotypes alongside their corresponding SNP markers. A quality control filter analysis was performed using call rate below 75% per markers and genotypes and MAF below 0.05 using the function qc.filtering from ASRgenomics R package (Gezan et al., 2022).
4.5 Selection, imputation and coverage of SNPs
Monomorphic SNPs and those with a Minor Allele Frequency below 5% were removed. Genotypes with a call rate below 75% were excluded. The final dataset comprised 605 selected SNPs and 267 genotypes. For the imputation of missing data, the LD-kNNi algorithm was used (Money et al., 2015). After filtering and imputation, SNPs were distributed across 20 soybean chromosomes (Figure 3), with positions shown equidistantly, not reflecting actual chromosome size.
.png) Figure 3 Number and equidistance of SNPs across the 20 soybean chromosomes |
4.6 Population analyses
Genetic diversity was estimated using expected heterozygosity (He) and observed heterozygosity (Ho) across loci. The genetic distance between populations was calculated using the Prevosti et al. (1975) method and the resulting distance matrix was employed in a hierarchical clustering analysis using the unweighted pair group method with arithmetic mean (UPGMA). The starting point for the clustering was the smallest distance and this method was chosen due its cophenetic correlation, estimated by the Mantel test with 10,000 permutations to construct a dendrogram.
The Mantel test was used to assess the fit between the hierarchical clustering and the original dissimilarity matrix. After clustering, the cutoff point for group formation was determined using the Mojena method. To evaluate the genetic relationships among soybean lines and the variation within populations, a pairwise distance matrix was calculated using the Pairwise method (Paradis, 2011). The resulting genetic distance matrix was then used to conduct a principal component analysis (PCA) to visualize the genetic variation. The PCA was plotted on a Cartesian plane, considering the first two principal components, where the specific explanatory capacity was determined by the eigenvalues. Confidence ellipses were added to the PCA plot, assuming a multivariate t-distribution at a 0.05 probability level.
5 Conclusions
This study reveals the existence of both phenotypic and genotypic intracultivar variation among the assessed soybean cultivars. The degree of variation observed differs, with cultivars P98Y11 and NA5909 exhibiting higher levels of diversity, while NS7000 presents a lower level of variation. This reflects the fact that the genome is not static but rather dynamic, constantly subject to genetic and environmental influences that shape diversity. In addition, these results strongly demonstrated that intra-cultivar variations offer valuable opportunities in soybean plant breeding programs as a breeding tool.
Acknowledgments
The authors thank the National Council for Scientific and Technological Development (Conselho Nacional de Desenvolvimento Científico e Tecnológico - CNPq) and the Minas Gerais State Agency for Research and Development (Fundação de Amparo à Pesquisa do Estado de Minas Gerais - FAPEMIG) for their support, and the Brazilian Federal Agency for Support and Evaluation of Graduate Education (Coordenação de Aperfeiçoamento de Pessoal de Nível Superior - CAPES). The authors acknowledge the support of the Brazilian National Council for Scientific and Technological Development (CNPq) research productivity scholarship. The authors thank the GDM Genetica do Brasil S. A. for their support. The authors have reviewed and edited the output and take full responsibility for the content of this publication.
Author Contributions
Conceptualization, E.L.R and A.T.B.; methodology, E.L.R, A.T.B., M.R.P.; software, M.R.P. and D.A.O.; validation, E.L.R., A.T.B., M.R.P. and D.A.O.; formal analysis, M.R.P. and D.A.O.; investigation, E.L.R., A.T.B., B.S.P., M.R.P., D.A.O., V.A.P.S., T.T.T.R.,A.G.S.G.S., C.H.S.; resources, A.T.B.; data curation, E.L.R., A.T.B., B.S.P., M.R.P., D.A.O., V.A.P.S., T.T.T.R.,A.G.S.G.S., C.H.S.; writing-original draft preparation, E.L.R; writing—review and editing, B.S.P. and A.T.B.; visualization, M.R.P. and D.A.O.; supervision, E.L.R.; project administration, E.L.R.; funding acquisition, A.T.B. All authors have read and agreed to the published version of the manuscript.
Conflict of Interest
The authors declare no conflicts of interest.
Data Availability
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Achard F., Boller B., and Mottet M.J., 2020, Single nucleotide polymorphisms facilitate distinctness-uniformity-stability testing of soybean cultivars for plant variety protection, Crop Science, 60(5): 2280-2303.
https://doi.org/10.1002/csc2.20201
Agorastos A.G., and Goulas C.K., 2005, Line selection for exploiting durum wheat (T. turgidum L. var. durum) local landraces in modern variety development program, Euphytica, 146(1-2): 117-124.
https://doi.org/10.1007/s10681-005-8495-3
Ahrent D.K., and Caviness C.E., 1994, Natural cross-pollination of twelve soybean cultivars in Arkansas, Crop Science, 34(2): 376-378.
https://doi.org/10.2135/cropsci1994.0011183X003400020013x
Amaral L. de O., Peluzio J.M., Afférri F.S., Carvalho E.V., and Diniz L.E.C., 2019, Pure line selection in a heterogeneous soybean cultivar, Crop Breeding and Applied Biotechnology, 19(3): 277-284.
Carneiro A.K., Peluzio J.M., Afférri F.S., Carvalho E.V., and Diniz L.E.C., 2019, Stability analysis of pure lines and a multiline of soybean in different locations, Crop Breeding and Applied Biotechnology, 19(4): 395-401.
https://doi.org/10.1590/1984-70332019v19n4a56
Du J., Grant D., Tian Z., Nelson R.T., Zhu L., Shoemaker R.C., and Ma J., 2010, SoyTEdb: A comprehensive database of transposable elements in the soybean genome, BMC Genomics, 11: 113.
Duan Z., Li Q., Wang H., He X., and Zhang M., 2023, Genetic regulatory networks of soybean seed size, oil and protein contents, Frontiers in Plant Science, 14: 1-12.
https://doi.org/10.3389/fpls.2023.1160418.
Falconer D.S., and Mackay T.F.C., 1996, Introduction to Quantitative Genetics (4th ed.), Addison Wesley Longman, Harlow, UK.
Fang Y., Han Y., Fang Y., Sun J., Lin C., Bukhari B., Zhou D., Liu B., Guo C., and Wang Y., 2025, Epigenetic regulation modulates seasonal temperature-dependent growth of soybean in Southern China, Plant Biotechnology Journal, 23(10): 4580-4601.
https://doi.org/10.1111/pbi.70243
Fasoula V.A., and Boerma H.R., 2005, Divergent selection at ultra-low plant density for seed protein and oil content within soybean cultivars, Field Crops Research, 91(2-3): 217-229.
https://doi.org/10.1016/j.fcr.2004.07.018
Gezan S.A., de Oliveira A.A., Galli G., and Murray D., 2022, ASRgenomics: An R package with complementary genomic functions, Version 1.1.0, VSN International, Hemel Hempstead, United Kingdom.
Hartley H.O., 1950, The maximum F-ratio as a short-cut test for heterogeneity of variance, Biometrika, 37(3-4): 308-312.
Haun W.J., Hyten D.L., Xu W.W., Gerhardt D.J., Albert T.J., Richmond T., Jeddeloh J.A., Jia G., Springer N.M., Vance C.P., and Stupar R.M., 2011, The composition and origins of genomic variation among individuals of the soybean reference cultivar Williams 82, Plant Physiology, 155(2): 645-655.
Hockett E.A., Eslick R.F., Qualset C.O., and Rogers M.E., 1983, Effects of natural selection in advanced generations of barley composite cross II, Crop Science, 23(4): 752-756.
Lu Y., Zhang C., Zhang L., et al., 2022, High genetic diversity and low population differentiation of a medical plant Ficus hirta Vahl., uncovered by microsatellite loci: Implications for conservation and breeding, BMC Plant Biology, 22: 334.
https://doi.org/10.1186/s12870-022-03734-2
Marand A.P., Jansky S.H., Zhao H., and Jiang J., 2019, Residual heterozygosity and epistatic interactions underlie the complex genetic architecture of yield in diploid potato, Genetics, 212(1): 317-332.
Medina G., Ribeiro G., and Brasil E.M., 2016, Participação brasileira na cadeia da soja: lições para o futuro do agronegócio nacional, Revista de Economia e Agronegócio, 13(1): 4-9.
Mendonça H.C., Santos J.V.M., et al., 2022, Genetic diversity and selection footprints in the genome of Brazilian soybean cultivars, Frontiers in Plant Science, 13: 842571.
https://doi.org/10.3389/fpls.2022.842571
Mendonça L.F., Zdziarski A.D., et al., 2020, Genomic prediction enables early but low-intensity selection in soybean segregating progenies, Crop Science, 60(1): 1-16.
https://doi.org/10.1002/csc2.20072
Mihelich N.T., Mulkey S.E., Stec A.O., and Stupar R.M., 2020, Characterization of genetic heterogeneity within accessions in the USDA soybean germplasm collection, The Plant Genome, 13(1): e20000.
https://doi.org/10.1002/tpg2.20000
Money D., Gardner K., Migicovsky Z., Schwaninger H., Zhong G.Y., and Myles S., 2015, LinkImpute: Fast and accurate genotype imputation for nonmodel organisms, G3: Genes|Genomes|Genetics, 5(11): 2383-2390.
https://doi.org/10.1534/g3.115.021667
Morgante M., Brunner S., Pea G., Fengler K., Zuccolo A., and Rafalski A., 2005, Gene duplication and exon shuffling by helitron-like transposons generate intraspecies diversity in maize, Nature Genetics, 37(9): 997-1002.
https://doi.org/10.1038/ng1615
Ninou E., Mylonas I., et al., 2022, Utilization of intra-cultivar variation for grain yield and protein content within durum wheat cultivars, Agriculture, 12(5): 661.
https://doi.org/10.3390/agriculture12050661
Paradis E., 2011, Analysis of Phylogenetics and Evolution with R (2nd ed.), Springer, New York, NY, USA.
https://doi.org/10.1007/978-1-4614-1743-9
Prevosti A., Ocaña J., and Alonso G., 1975, Distances between populations of Drosophila subobscura, based on chromosome arrangements frequencies, Theoretical and Applied Genetics, 45(6): 231-241.
Rasmusson D.C., and Phillips R.L., 1997, Plant breeding progress and genetic diversity from de novo variation and elevated epistasis, Crop Science, 37(2): 303-310.
https://doi.org/10.2135/cropsci1997.0011183X003700020001x
Reynolds M.P., and Braun H.-J., 2022, Wheat Improvement: Food Security in a Changing Climate, Springer, Cham, Switzerland.
https://doi.org/10.1007/978-3-030-90673-3
Roy P.S., Patnaik A., Rao G.J.N., Patnaik S.S.C., Chaudhury S.S., and Sharma S.G., 2016, Participatory and molecular marker assisted pure line selection for refinement of three premium rice landraces of Koraput, India, Agroecology and Sustainable Food Systems, 41(2): 167-185.
https://doi.org/10.1080/21683565.2016.1258607
Salgotra R.K., and Chauhan B.S., 2023, Genetic diversity, conservation, and utilization of plant genetic resources, Genes, 14(1): 174.
https://doi.org/10.3390/genes14010174
Sandhu D., Morawiecki A., Brar G.S., Naik S., and Bhattacharyya M.K., 2017, The endogenous transposable element Tgm9 is suitable for generating knockout mutants for functional analyses of soybean genes and genetic improvement in soybean, PLoS One, 12(7): e0180732.
https://doi.org/10.1371/journal.pone.0180732
Santos P.S.J., Abreu A.F.B., and Ramalho M.A.P., 2002, Seleção de linhas puras no feijão ‘carioca’, Ciência e Agrotecnologia, 20(4): 1492-1498.
Shapiro S.S., and Wilk M.B., 1965, An analysis of variance test for normality (complete samples), Biometrika, 52(3-4): 591-611.
Tayade R., Imran M., Ghimire A., Khan W., Nabi R.B.S., and Kim Y., 2023, Molecular, genetic, and genomic basis of seed size and yield characteristics in soybean, Frontiers in Plant Science, 14: 1195210.
https://doi.org/10.3389/fpls.2023.1195210
Tokatlidis I.S., 2015, Conservation breeding of elite cultivars, Crop Science, 55(6): 2417-2434.
https://doi.org/10.2135/cropsci2015.01.0020
Tokatlidis I.S., Papadopoulos I.I., Papathanasiou F., and Vlachostergios D.N., 2008, Variability within cotton cultivars for yield, fiber quality and physiological traits, The Journal of Agricultural Science, 146(4): 483-490.
United States Department of Agriculture (USDA), International Production Assessment Division, 2025, Brazil - Soybean Area, Yield and Production.
https://ipad.fas.usda.gov/countrysummary/Default.aspx?id=BR&crop=Soybean
Vilela N.J.D., Silva F.L., et al., 2024, Multiline is a strategy for homeostasis and Asian soybean rust management in agriculture, Genetics and Molecular Research, 23(1): 1.
Yates J.L., Smith T.J., Jones S.I., and Stupar R.M., 2012, SSR-marker analysis of the intracultivar phenotypic variation discovered within 3 soybean cultivars, Journal of Heredity, 103(4): 570-578.
https://doi.org/10.1093/jhered/ess015
Zimmer G., Miller M.J., Steketee C.J., Jackson S.A., Tunes L.V.M., and Li Z., 2021, Genetic control and allele variation among soybean maturity groups 000 through IX, The Plant Genome, 14(3): e20146.
https://doi.org/10.1002/tpg2.20146




. FPDF(win)
. FPDF(mac)
. HTML
. Online fPDF
Associated material
. Readers' comments
Other articles by authors
. Ewerton Resende
. Adriano Bruzi
. Bruna de Paula
. Mateus Piza
. Danyllo Oliveira
. Vitório Antônio de Souza
. Taine da Rocha
. Afrânio Gabriel G Santiago
. Carlos Henrique Souza
Related articles
. Glycine max L. Merrill.
. Plant breeding
. Genetic diversity
. Genetic stability
Tools
. Post a comment